Dataanalyse åpent hav
Vi bruker statistiske analyser av telledata til å tallfeste forventet forekomst av sjøfugl i heldekkende områder. Først analyserer vi sammenhengen mellom forekomst av sjøfugl og diverse geografiske variable. Denne sammenhengen blir deretter brukt til å regne ut forventet, eller predikert, forekomst av sjøfugl i heldekkende områder. Her gir vi en detaljert beskrivelse av metodikken vi har brukt.
Statistisk modellering
Transektdataene dekker kun tynne striper over de store havområdene hvor man ønsker å predikere sjøfuglenes utbredelse. Som en følge av flokkdannelse hos fuglene inneholder dataene stor lokal variasjon i tetthet. I den grad denne variasjonen ikke kan forklares av spesifikke geografiske områder er det ønskelig å fjerne den fra prediksjonene. For å fjerne denne typen tilfeldig lokal variasjon, og for å kunne predikere tettheter i heldekkende områder, også i områder hvor man har lite data, ble dataene modellert med geografisk fikserte forklaringsvariabler i tostegs modeller. Modellene ble deretter brukt til å predikere tettheten av de ulike artene i et rutenett hvor forklaringsvariablene var kjent.
Analysene ble utført separat for alle arter, sesonger og havområder. For å bedre estimatene i grensene mellom havområdene, ble data fra 200 km inn i tilgrensende havområder inkludert i analysene av et gitt havområde.
Aggregering av data
Før dataene ble modellert ble de slått sammen til en romlig skala som var hensiktsmessig i forhold til det totale analyseområdet. Hensikten med denne typen aggregering er å tilpasse observasjonsskalaen til skalaen for det geografiske mønsteret man ønsker å predikere. Dermed reduseres betydningen av pseudoreplikasjon, utvalgsstørrelsen blir mer håndterbar, og man glatter ut tilfeldig lokal variasjon.
Vi valgte å bruke en observasjonsskala på 50 km. Som en følge av hyppige stans i observasjonene og endring av transektretning var aggregeringen av data komplisert å gjennomføre på en systematisk måte. Vi valgte en prosedyre hvor aggregeringen foregikk suksessivt og kronologisk langs de utkjørte transektene. En observasjon ble inkludert i et aggregert punkt hvis distansen fra punktet til midtpunktet i det aggregerte punktet var mindre enn 25 km, og hvis tidsforskjellen mellom punktet og gjennomsnittet i det aggregerte punktet var mindre enn 6 timer. Som en følge av metodikken varierte transektlengden mellom de aggregerte punktene, og transektlengde ble derfor korrigert for i analysene. Aggregerte punkter hvor transektlengde var mindre enn 5 km ble ekskludert fra utvalget.

Foto: Per Fauchald
To-stegs analyser
Pelagiske organismer, inkludert sjøfugl, har en klumpvis romlig fordeling. Dette betyr i praksis at romlige data av denne typen organismer inneholder mange observasjoner hvor man ikke har talt noen individer (nullobservasjoner), og noen observasjoner hvor man har talt svært mange individer. På grunn av de mange nullobservasjonene kalles denne typen data for zero-inflated data. To-stegs modellering er en effektiv måte å håndtere denne typen data på.
Hensikten med modellene er å estimere sammenhengen mellom observert tetthet av sjøfugl og geografisk fikserte forklaringsvariable, for deretter å bruke disse estimatene til å predikere tettheten i heldekkende områder hvor forklaringsvariablene er kjent.
Første steg i to-stegs-analysene var å modellere tilstedeværelse/fravær av fugl. I dette steget ble det brukt binomisk fordeling med ”logit link”-funksjon. I steg to modellerte vi antallet fugl i de observasjonene hvor fugl faktisk var til stede. I dette steget ble det brukt Gamma-fordeling med ”log link”-funksjon. Ideelt skulle man på dette trinnet ha brukt en trunkert Poisson eller trunkert negativ binomial fordeling. Sannsynligvis fordi en del observasjoner hadde svært høye verdier ville ikke disse modellene konvergere, men Gamma-modellene fungerte tilfredsstillende som en tilnærming.
For å modellere sammenhengene med de geografisk fikserte forklaringsvariablene, ble det brukt ikke-lineære Generalized Additive Models (GAM) fra ”mgcv”-biblioteket i R v.2.10.1 (R Development Core team, 2009). Forklaringsvariablene var x- og y-retning (hhv vest-øst og sør-nord), dyp (d) og distanse til kyst (c). Geografisk posisjon ble modellert med en todimensjonal glattingsfunksjon: g(x,y). d og c ble modellert med endimensjonale glattingsfunksjoner: s(·). ”Tensor produkt”-glatting med kubiske regresjonssplinter ble brukt som basis. Optimal glatting ble definert av Generalized Cross Validation (GCV).
I første steg ble sannsynligheten for tilstedeværelsen av fugl modellert med ”logit link”- og binomial fordeling:
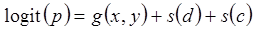
I andre steg ble antallet fugl modellert i de observasjonene hvor antallet fugl var større enn null med ”loge link”- og Gamma-fordeling:
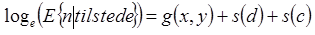
hvor E er forventning. Utkjørt distanse (loge-transformert) i hver observasjon ble brukt som ”offset” i modellene.
Modellprediksjoner
Basert på estimatene i modellene ble ”predict”-funksjonen i ”mgcv”-biblioteket brukt til å predikere forventet geografisk fordeling av fugl på et 10×10 km2 rutenett som dekker studieområdet i hver sesong. Predikert sannsynlighet for tilstedeværelsen av fugl i en gitt rute ble funnet ved hjelp av den binomiale modellen. På samme måte ble forventet antall fugl i en gitt rute funnet med Gamma-modellen. Forventet antall fugl i en gitt rute er dermed gitt ved:
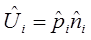
Usikkerhet: Bootstrap-analyser
Usikkerhet i estimatene vil avhenge av dekningsgrad (utvalgsstørrelse) og variasjon i utbredelse hos den enkelte art. Usikkerheten til prediksjonene er ikke helt enkelt å beregne, og vi valgte å utføre bootstrap-analyser for å finne standardfeil og konfidensintervall for prediksjonene med hensyn til geografisk utbredelse og årlig tallrikhet i Barentshavet.
Analysene, som beskrevet over, ble gjennomført for 2000 bootstrap-utvalg (tilfeldig sampling av datasettet med tilbakelegging). Estimatene fra bootstrap-utvalgene var log-normalt fordelt, og standardfeil ble beregnet for hver enkelt log10-transformerte verdi. 95% konfidensintervall ble hentet fra utvalget.
Ved beregning av usikkerhet med hensyn til årlig tallrikhet, reflekterer bootstrap-utvalget både usikkerhet med hensyn til forskjeller mellom år, men også usikkerhet med hensyn til den gjennomsnittlige tallrikheten i studieområdet (interseptet). For arter med utbredelse i utkanten av studieområdet var usikkerheten i interseptet relativt stor. Interseptet ble derfor standardisert lik gjennomsnittlig tallrikhet (over alle år) fra analysen av det originale utvalget. Konfidensintervall og standardfeil representerer derfor usikkerhet med hensyn til forskjeller mellom år og ikke usikkerhet med hensyn til gjennomsnittlig tallrikhet.